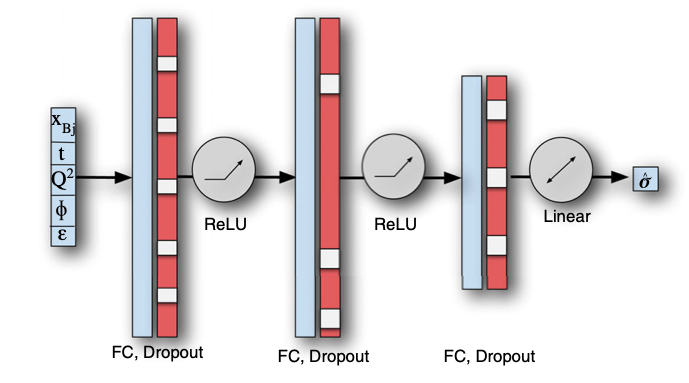
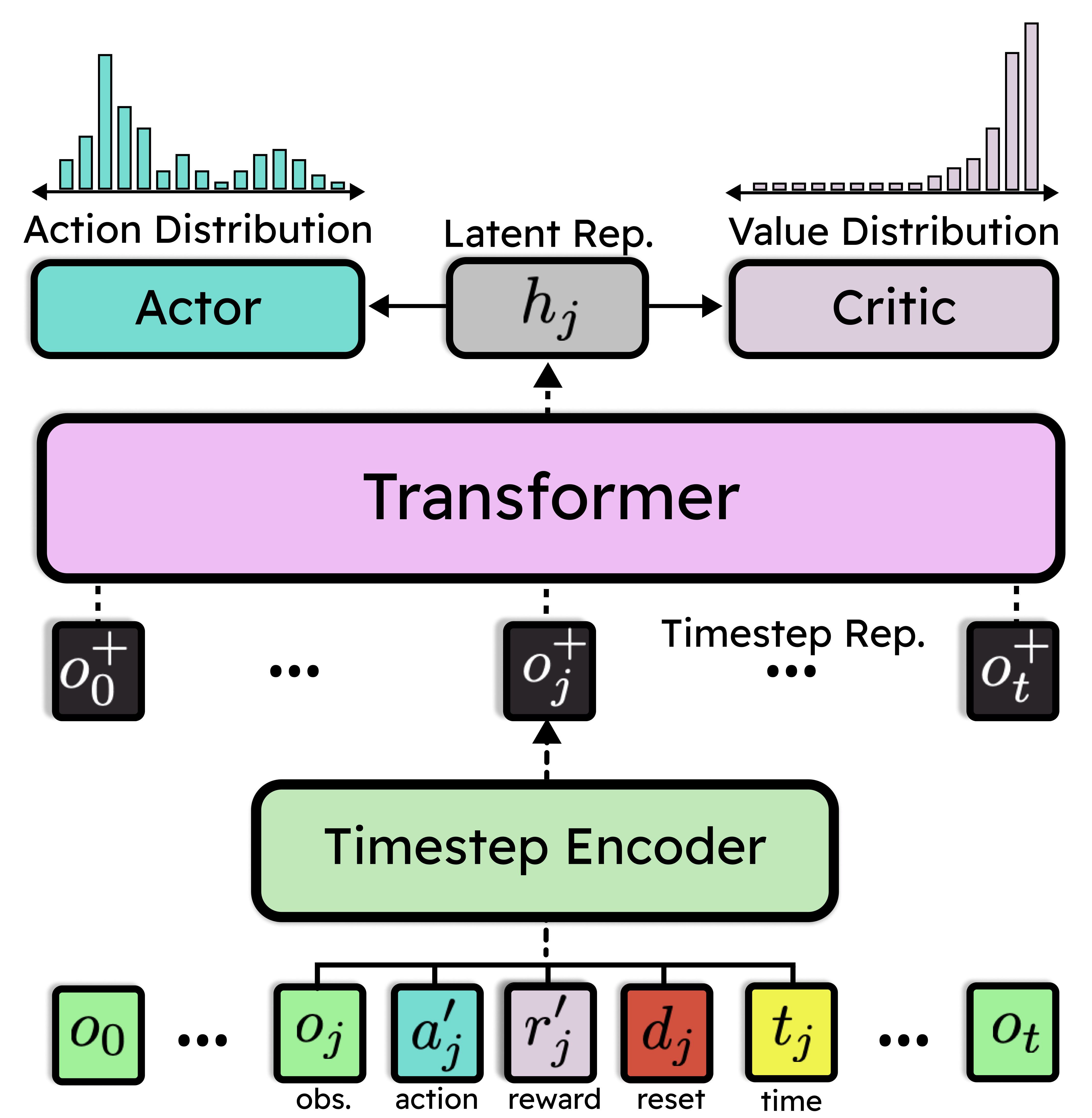
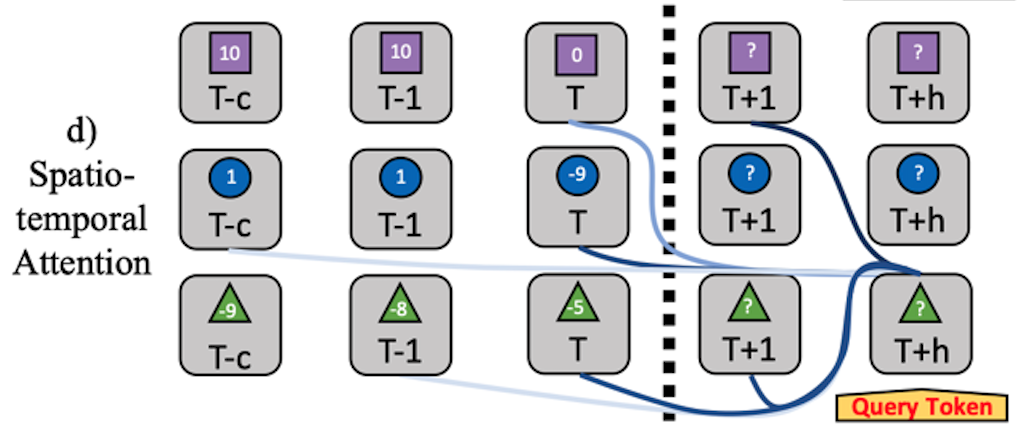
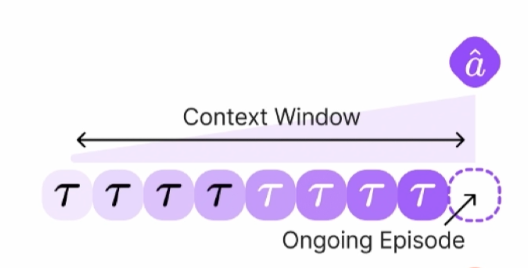
Jake Grigsby

I am a third year CS PhD student at UT Austin, working with Prof. Yuke Zhu and the Robot Perception and Learning Lab. My research focuses on generalization and long-term memory in deep reinforcement learning. Before coming to Austin, I studied Math and CS at the University of Virginia, where my research was advised by Prof. Yanjun Qi.
Research
-
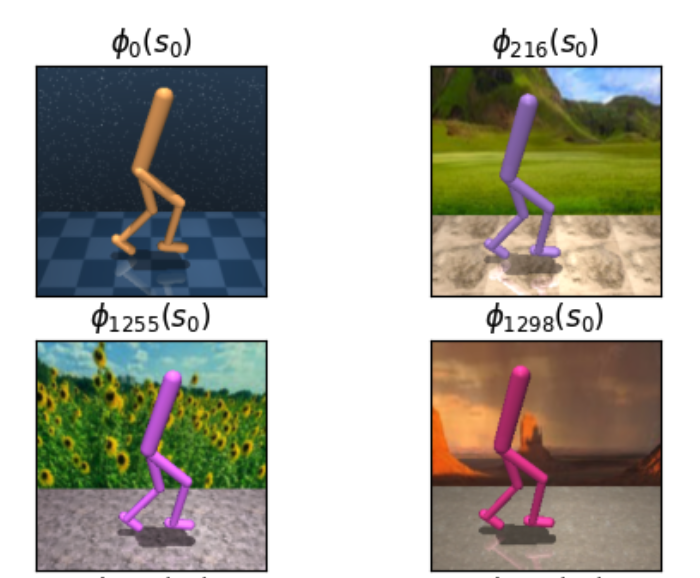
-
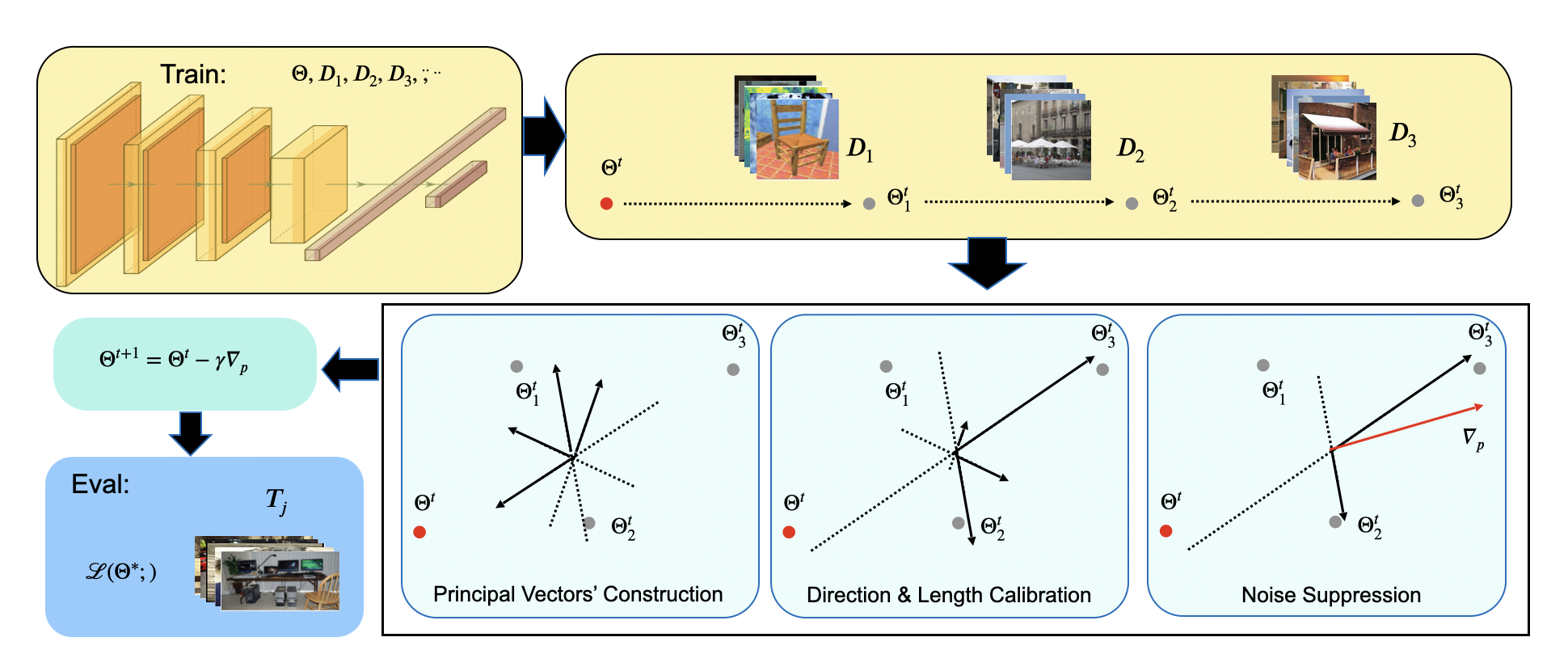
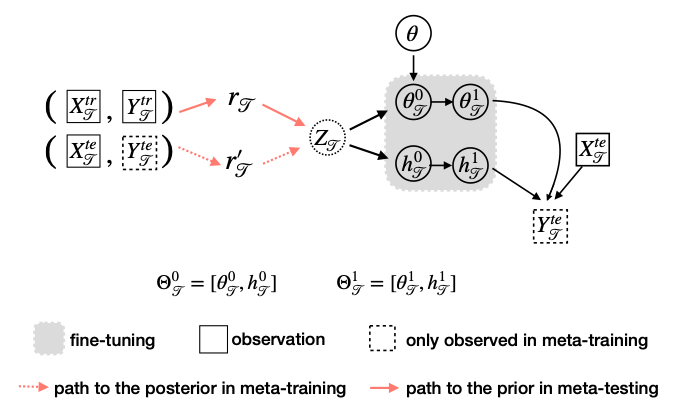 ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-LearningConference on Uncertainty in Artificial Intelligence 2022
ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-LearningConference on Uncertainty in Artificial Intelligence 2022 -
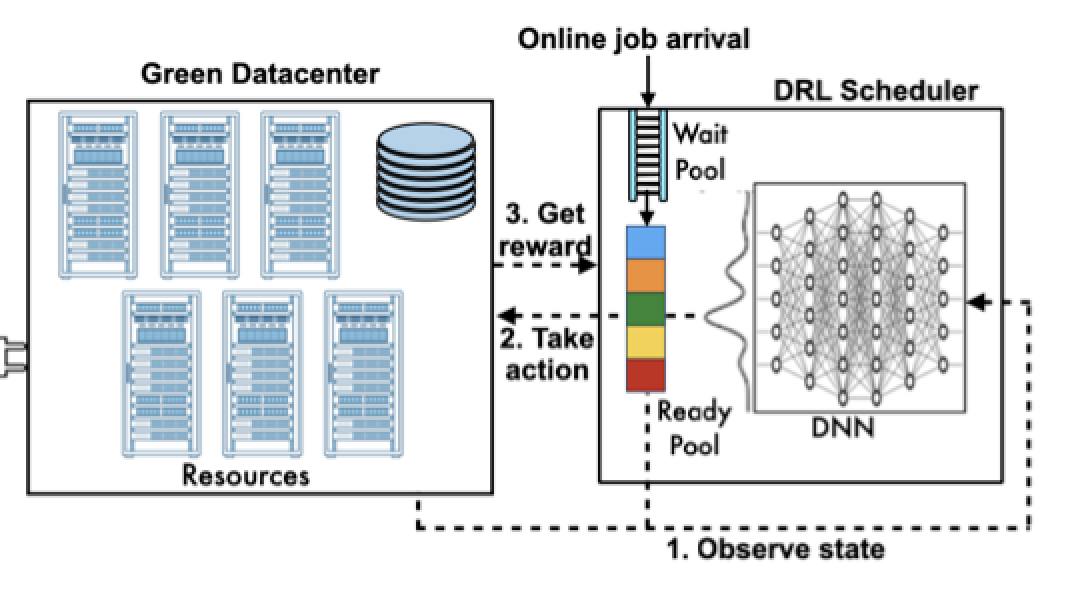 RARE: Renewable Energy Aware Resource Management in DatacentersWorkshop on Job Scheduling for Parallel Processing 2022
RARE: Renewable Energy Aware Resource Management in DatacentersWorkshop on Job Scheduling for Parallel Processing 2022 -
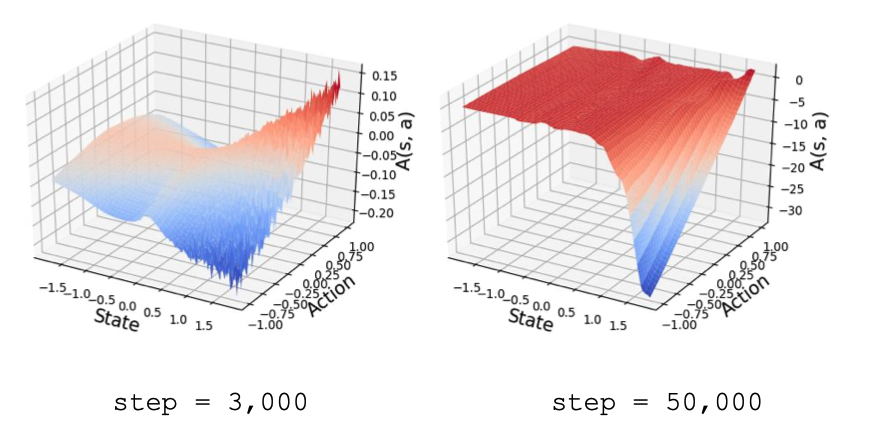 A Closer Look at Advantage-Filtered Behavioral Cloning in High-Noise DatasetsUVA Distinguished Major Thesis 2021
A Closer Look at Advantage-Filtered Behavioral Cloning in High-Noise DatasetsUVA Distinguished Major Thesis 2021 -